數據庫中的索引,原理是什么?為什么查詢使用索引就會快?
想想漢語字典的拼音和部首索引就可以了,就是這么簡單 。
其他網友觀點很高興能夠看到和回答這個問題!
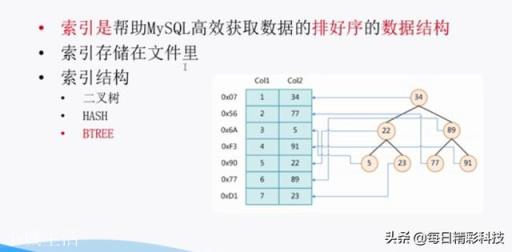
什么是數據庫索引?數據庫中的索引類似于書籍中的目錄,目錄可以快速獲取信息,而不需要閱讀整本書 。
在數據庫中,索引可以讓數據庫程序在不掃描整張表的情況下找到所需的數據 。本書包含一組章節,并列出包含章節的頁碼 。數據庫中的索引是表中一列或多列中的一組值,相應的索引列表代表這些值 。
文章插圖
索引字段可以是單個字段也可以是多個字段的組合,如果是多個字段的組合,其索引值的排列首先按第一個字段值進行排列,如果其值相同,再按第二個字段的值進行排列,以此類推 。
使用索引的意義有哪些?數據庫中的糖指數類似于書中的目錄值,用于提高信息檢索速度 。
使用索引搜索數據不需要掃描整個表格,也不需要快速搜索數據 。

文章插圖
索引使用的成本
糖指數需要占據物理內存之外的位置 。創建和運行索引需要一定的時間 。
?更新索引表時,服務數據重建的速度要放慢 。
數據庫索引類別索引不需要重新排列文件中記錄的順序 。一個文件可以有多個相互關聯的索引,每個索引支持鍵碼,通過索引可以快速訪問文件中的記錄 。
文章插圖
1、靜態索引
靜態索引是在創建文件時創建的索引結構 。文件完成后,只有在重新組織時才能修改 。2、動態索引
動態索引是在創建文件時創建的索引結構 。當執行插入和刪除等操作時,索引結構本身會發生變化 。
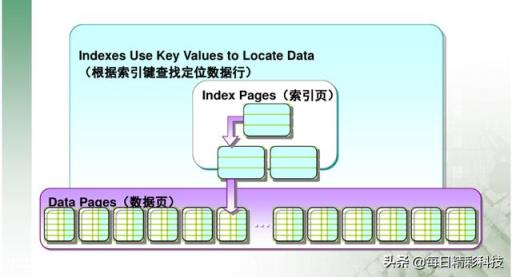
索引的缺點在添加、修改、刪除數據時,需要維護索引樹,有一定的性能影響 。當頻繁維護樹B時,分頁和整合會產生大量的索引碎片,同時需要維護索引的有效性;但存在一個問題也需要注意 。
文章插圖
在一段時間內發生索引(主要是添加、修改、刪除數據 。如果頁面已經完成,則需要對頁面進行分割,頻率分開,導致索引碎片增多),從而導致索引頁面分割 。這樣會導致隨機訪問I/O文件,而不是按照I/O的順序進行讀取,所以對索引的訪問速度會比較慢 。如果碎片數量太多,數據庫可能不會使用索引(太慢,數據庫會選擇更高效的執行計劃) 。
如何更好地使用數據庫索引索引字段非常小,最好有一個值,如整個值,如INT;對于經常變化的字段,盡量不要創建索引,索引管理成本很高,生成索引碎片比較容易;如定期索引管理,修正索引碎片;不創建或維護不必要的重復索引,會增加數據變化(添加、修改、刪除)的成本 。使用唯一的高字段創建索引,不能在弱字段如樓層中創建索引 。

文章插圖
在SQL句子In中,盡量不要使用函數、運算符或表達式來計算where,這可能會導致索引的錯誤使用;必須避免在子空間語句中包含空值,否則會導致引擎在表被完全掃描時停止使用索引;你應該避免在句子中使用任何! =或<<,否則會導致引擎停止使用索引來掃描表 。
以上便是我的一些見解和回答,可能不能如您所愿,但我真心希望能夠對您有所幫助!不清楚的地方您還可以關注我的頭條號“每日精彩科技”我將竭盡所知幫助您!
碼字不易,感覺寫的還行的話,還請點個贊哦!
其他網友觀點數據庫索引可以理解成圖書館的書架,書架按書目分類,或者理解成一本書的目錄 。想想如果沒有這些目錄,要找一本書中內容,就要從頭把書翻一遍,或者把圖書館的書都找一遍,這樣會有多慢?
數據庫建立索引也是這個原理,數據有了分類目錄了,查詢數據的時候,先查找目錄就會快了很多 。
不過對現在的海量數據來講,有了索引還是杯水車薪,查詢依然很慢,而且建立索引要占用額外的存儲空間,對數據庫來講存貯空間是非常值錢的,商業數據庫存貯空間收費昂貴 。
真正的海量數據存貯,查詢效率都是用計算機硬件堆起來的,就是用錢堆起來的,不要想在軟件上做點優化就會有多少本質的提高 。
【數據庫中的索引,原理是什么?為什么查詢使用索引就會快?】具體硬件優化有很多手段,前端查詢,數據庫緩存,分布式應用等等,要想掌握好數據庫的優化,去看看實際的商業應用案例最好,書本上的那些東西,沒多大意義 。
推薦閱讀







- 科學訓練狗狗中的十對十錯
- 微生物肥:新型肥料家族中的“大哥大”
- 元妃點戲,揭露了《紅樓夢》中的哪些秘密?元妃點戲暗示了什么?
- 熱戀中的情話
- 交換機應用中的六種安全設置
- 瀉鹽的作用是什么
- 女人在戀愛中的錯誤做法
- 謹防留守中的哈士奇犬患憂郁癥
- 解酒的水果有哪些
- 肉類保鮮技術-肉類的基本分類