hbase三種查詢方式 hbase使用教程
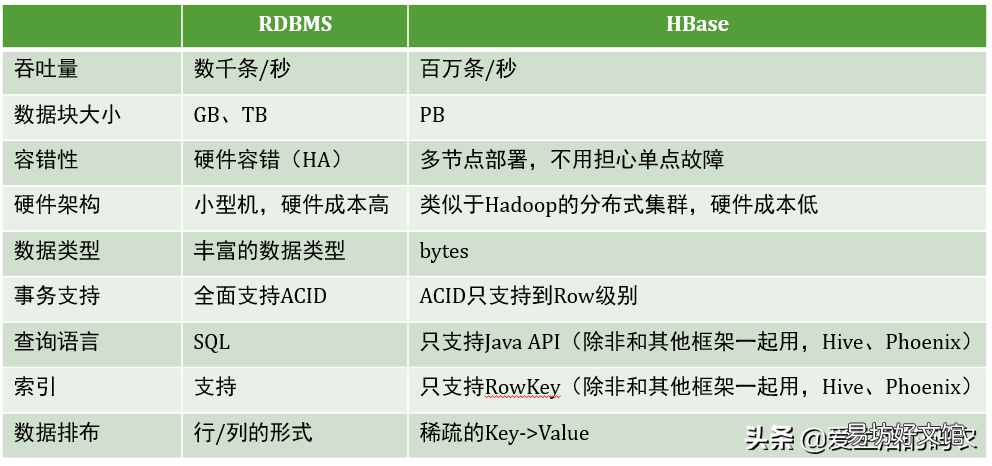
一 初識HBase1.1 HBase的概念HBase是一分布式的、面向列的開源NoSQL海量數據庫存儲系統,它的理論原型是 Google 的 BigTable 論文 。通俗地講,HBase 是一個具有高可靠性、高性能、面向列、可伸縮的分布式存儲系統 。它可以處理分布在數千臺服務器上的PB級海量數據 。
HBase是基于HDFS存儲數據的,HDFS是部署在商業服務器上的,并且具有高容錯性 。基于HDFS,就意味著HBase具有超強的擴展性和容錯性 。
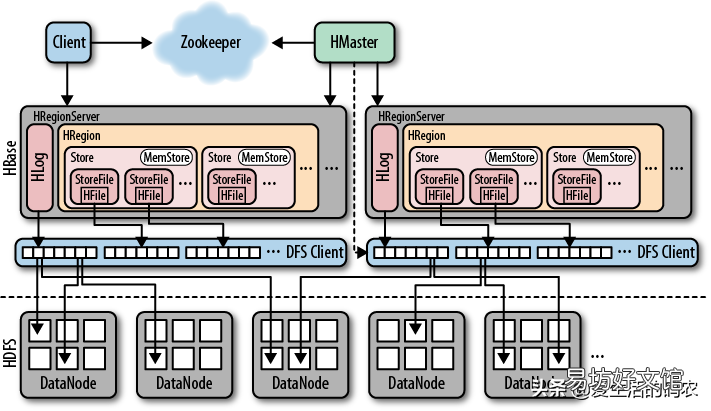
在詳細介紹HBase之前,我們一起來看看HBase的架構,如下圖所示:
文章插圖

文章插圖
HBase的系統架構
HBase采用的是key/value的存儲格式,這就能保證,即使數據量增大,也不會導致查詢性能大幅度下降 。因為 HBase 是一個面向列存儲的數據庫,當表的字段很多時,可以把其中幾個字段放在一部分機器上,而另外幾個字段放到另一部分機器上,充分分散負載的壓力 。如此復雜的存儲結構和分布式存儲方式,帶來的代價就是即便是存儲很少的數據,也不會很快 。
我們可以看出,HBase是那種既不快,又慢的不明顯的數據庫,因此,它主要應用在以下兩種情況的查詢:
- 單表數據量不能太大(千萬級別),并發量不能太高 。
- 對數據需求分析不要求特別及時,同時也不要求太靈活 。
2.1.2 列式存儲數據HBase是根據列族來存儲數據的 。列族下面可以有非常多的列,在建表時,必須指定列族,但是不用指定列 。
2.1.3 稀疏性存儲結構稀疏主要體現在HBase的列的靈活性上面,在HBase的列族中,可以指定任意多的列,在列數據為空的情況下,HBase表是不會占用存儲空間的 。
2.1.4 易擴展性一個是基于上層處理能力(RegionServer)的擴展,通過橫向添加 RegionSever 的機器,進行水平擴展,提升 HBase 上層的處理能力,提升HBase服務更多 Region 的能力 。另外一個是基于存儲能力(HDFS)的擴展 。
文章插圖
文章插圖
HBase和數據庫的比較
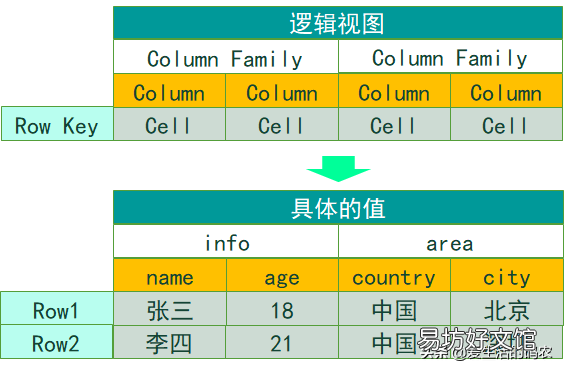
2.2 HBase的邏輯結構在下圖中,列簇(Column Family)對應的值就是 info 和 area ,列( Column 或者稱為 Qualifier )對應的就是 name 、 age 、 country 和 city ,Row key 對應的就是 Row1 和 Row2,Cell 對應的就是具體的值 。
- Row key :表的主鍵,按照字典序排序 。
- 列簇:在 HBase 中,列簇將表進行橫向切割 。
- 列:屬于某一個列簇,在 HBase 中可以進行動態的添加 。
- Cell : 是指具體的 Value。
- Version :在這張圖里面沒有顯示出來,這個是指版本號,用時間戳(TimeStamp )來表示 。
文章插圖
文章插圖
HBase的邏輯結構
看完這張圖,是不是有點疑惑,怎么獲取其中的一條數據呢?既然 HBase 是 KV 的數據庫,那么當然是以獲取 KEY 的形式來獲取到 Value 啦 。在 HBase 中的 KEY 組成是這樣的:

文章插圖
文章插圖
cell的結構
KEY 是由 Row key 、CF(Column Family) 、Column 和 TimeStamp 組成的 。
TimeStamp 在 HBase 中的作用就是版本號,因為在 HBase 中有著數據多版本的特性,所以同一個 KEY 可以有多個版本的 Value 值(可以通過配置來設置多少個版本) 。查詢的話是默認取回最新版本的那條數據,但是也可以進行查詢多個版本號的數據 。
2.3 HBase的物理結構
文章插圖
文章插圖
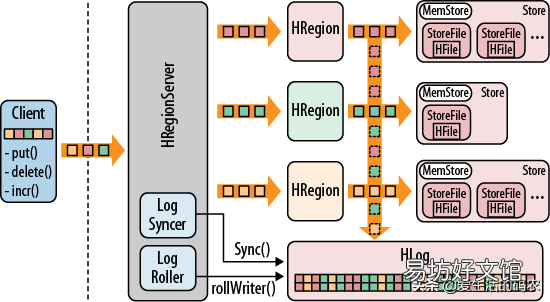
HBase的物理結構
2.3.1HRegionServerHRegionServer 就是一個機器節點,包含多個 HRegion ,但是這些 HRegion 不一定是來自于同一個 Table 。直接面對用戶的讀寫請求,是真正干活的節點 。它的主要功能如下:
- 為Table分配HRegion 。
- 處理來自客戶端的讀寫請求,和底層的HDFS進行交互,并將數據存儲到HDFS中 。
- 負責單個HRegion變大后的拆分 。
- 負責StoreFile的合并工作 。
2.3.2 HRegion每一個HRegion都包含多個Store,一個Store就對應一個列族的數據,而一個Store可以有多個StoreFile 。HRegion 是 Hbase 中分布式存儲和負載均衡的最小單元,但不是存儲的最小單元 。每一個HRegion都有開始的RowKey和結束的RowKey,代表著存儲的Row的范圍 。
2.3.3 Store(文件存儲區)Store 對應著的是 Table 里面的 Column Family,不管有 CF 中有多少的數據,都會存儲在 Store 中,這也是為了避免訪問不同的 Store 而導致的效率低下 。一個 CF 組成一個 Store ,默認是 10 G,如果大于 10G 會進行分裂 。Store 是 HBase 的核心存儲單元,一個 Store 由 MemStore 和 StoreFile 組成 。
2.3.3.1 MemStore每個Store都包含一個MEMStore實例,MemStore是內存的存儲對象,當 MemStore 的大小達到一個閥值(默認大小是 128M)時,如果超過了這個大小,那么就會進行刷盤,把內存里的數據刷進到 StoreFile 中,即生成一個快照 。目前HBase 會有一個線程來負責MemStore 的flush操作 。
2.3.3.2StoreFileStoreFile底層是以 HFile 的格式保存數據 。
2.3.4 StoreFile和HFile的物理結構StoreFile 以 HFile 格式保存在 HDFS 上,HFile 文件是不定長的,長度固定的只有其中的兩塊:Trailer 和 FileInfo 。
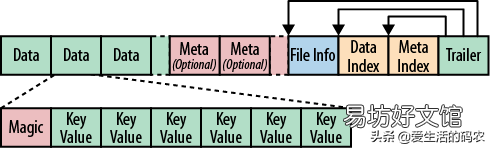
文章插圖
文章插圖
StoreFile的物理結構
HFile 里面的每個 KeyValue 對就是一個簡單的 byte 數組 。但是這個 byte 數組里面包含了很 多項,并且有固定的結構 。

文章插圖
文章插圖
HFile的物理結構
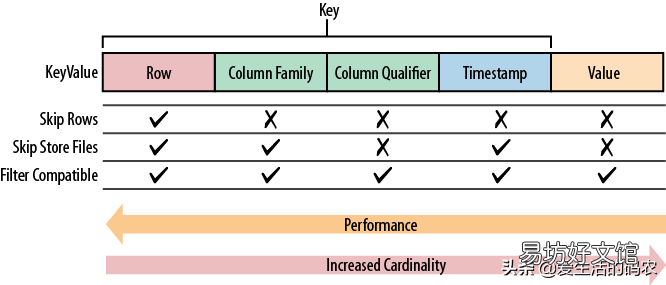
分別表示Key 的長度和 Value 的長度 。緊接著是RowKey 的長度,緊接著是 RowKey,然后是 Family 的長度,然后是 Family,接著是 Qualifier,然后是兩個固定長度的數值,表示 Time Stamp 和 Key Type(Put/Delete) 。Value 部分沒有這么復雜的結構,就是純粹的二進制數據了 。
三 HBase的底層架構
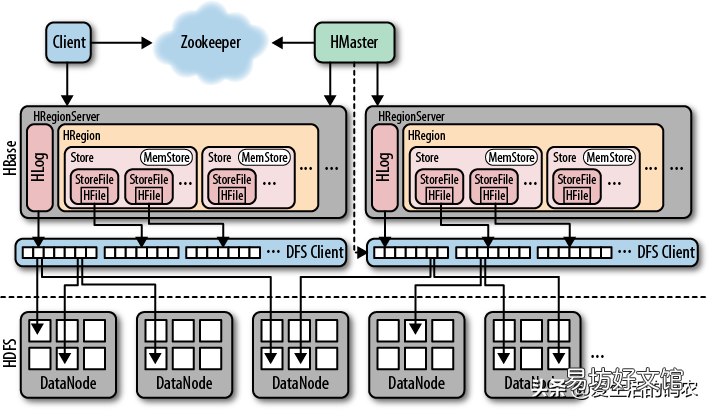
文章插圖
文章插圖
HBase的底層架構
從HBase的架構圖上可以看出,HBase中的組件包括Client、Zookeeper、HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等 。
3.1 ClientClient在訪問HBase之前,先訪問ZooKeeper找到數據所在的HRegion 。Client中有訪問HBase的接口,另外Client還維護了對應的Cache來加速HBase的訪問,比如緩存元數據 。
3.2 ZooKeeper① HBase 通過ZooKeeper來做 Master 的高可用
通過ZooKeeper來保證集群中只有一個Master在運行,為HBase提供了Failover機制,如果Master發生意外會通過競爭機制產生選舉新的Master,避免Master節點的單點故障問題 。
② 通過ZooKeeper監控HRegionServer的狀態,當HRegionServer有異常,或者有新的HRegionServer上線時,會通過回調方式告訴MasterRegionServer有節點的上下線信息
③ 存儲HBase的Schema,包括有哪些Table,每個Table有哪些Column Family信息 。
3.3MasterRegionServerMaster 是集群的主節點,可以配置成HA的形式 。Master 的工作并不高,因為Client 訪問 HBase 上數據的過程并不需要 Master 參與(尋址訪問 zookeeper 和 RegioneServer,數據讀寫訪問 RegioneServer),Master 的負載很低 。他的主要工作如下:
- 負責HRegionServer的負載均衡 。
- 發現失效的HRegionServer之后,將該HRegionServer上的Region分配給其他HRegionServer 。
- 為HRegionServer分配Region 。
- 負責HDFS上的HBase的垃圾文件的回收 。
- 維護Table和Region的元數據,處理 Schema 更新請求(表的創建,刪除,修改,列簇的增加等等)
3.4 HRegionHRegion的功能參見 2.3.2 HRegion
3.5 StoreStore的功能參見 2.3.3 Store
3.6 HFileHFile是存儲在HDFS中的二進制文件,實際上,StoreFile就是對Hfile做了輕量級包裝,StoreFile底層是HFile 。
3.7 HLogHLog(WAL log):WAL(Write-Ahead-Log)意為預寫日志,在 RegionServer 在插入和刪除數據的過程中,用來記錄操作內容的一種日志,主要用來做災難恢復使用,HLog記錄數據的所有變更,一旦region server 宕機,就可以從log中進行恢復 。
WAL是保存在HDFS上的持久化Hadoop Sequence File文件 。數據到達 Region 時先寫入WAL,然后被加載到MemStore中 。這樣就算Region宕機了,操作沒來得及執行持久化,在重啟的時候從WAL開始加載數據并執行 。跟Redis的AOF類似 。
- 在每個HRegionServer上,所有的HRegion都共享一份HLog,在寫入數據時先寫入WAL,成功之后再寫入MemStore 。當MemStore的大小達到一個閥值(默認大小是 128M)時,就會形成一個一個的StoreFile 。
- WAL的狀態是可以關閉的,關閉之后增刪改的操作會快一些,但是會犧牲掉數據的可靠性 。當然,我們也可以采用異步的方式寫入WAL(默認間隔是1秒鐘) 。
- HBase中的WAL文件是一個滾動日志數據結構,一個WAL實例包含多個WAL文件,在WAL的大小超過一定的閥值,或者WAL所在的HDFS文件塊要滿了的時候,WAL會觸發滾動操作 。
4.1 HBase讀數據過程
- 客戶端通過 ZooKeeper 集群,根據-ROOT-表和.META.表,找到目標數據所在的 RegionServer(就是要找到數據所在的 Region 的主機地址)
- 與目標的 RegionServer 進行通信,查詢目標數據 。
- RegionServer 定位到目標數據所在的 Region,發出查詢請求 。
- Region 分別在Block Cache(讀緩存),Memstore 和StoreFile(HFile)中查找目標數據,并將查詢到的所有數據進行合并,此處的所有數據是指,同一條數據包含不同的版本(Timestamp)的數據 。
- 將從HFile中查詢到的數據塊(Block,HFile的數據存儲單元,默認大小是128MB)緩存到Block Cache中,然后將最新的數據返回給客戶端 。
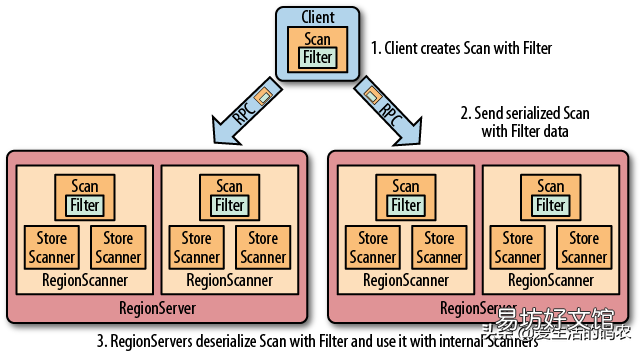
文章插圖
文章插圖
HBase的讀機制
4.2 HBase寫數據過程
- Client 先訪問ZooKeeper,根據 RowKey 查詢目標數據位于哪個RegionServer對應的 Region 中 。
- Client 向目標RegionServer 進行通信,并提交寫請求 。
- RegionServer 找到目標 Region,Region 檢查數據的格式是否與 Schema 一致 。
- 如果客戶端沒有指定版本,則獲取當前系統時間作為數據版本 。
- 將數據順序寫入(追加)到 WAL Log
- 將數據更新寫入 Memstore,數據會在MemStore中排序 。
- 判斷 Memstore 的是否需要 flush 為 StoreFile 文件 。
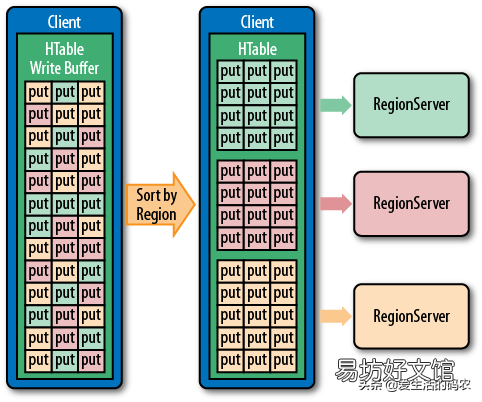
文章插圖
文章插圖
HBase的寫機制
4.3 HBase的寫為什么比讀快HBase能夠提供實時計算服務的根本原因是其架構和底層數據結構決定的,Hbase底層的存儲引擎為LSM-Tree(Log-Structured Merge-Tree) 。
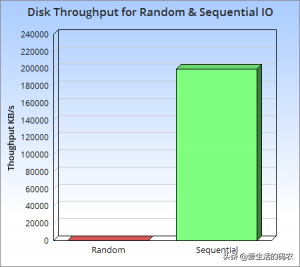
LSM的核心思想是放棄部分讀能力,換取寫入的最大化能力 。LSM的原則就是,先將最新的數據駐留在內存中,等到積累足夠多時,再使用歸并排序的方式將內存中的數據追加都磁盤的隊尾 。另外,LSM的寫入是磁盤的順序寫,數據寫入速度也很穩定 。我們知道磁盤的順序寫和內存寫性能相差不大,但是順序寫磁盤速度要比隨機寫磁盤快至少三個數量級!
不過讀取的時候稍微麻煩,需要合并磁盤中歷史數據和內存中最近修改操作,這樣磁盤在尋址耗時就遠遠大于磁盤順序讀取的詩句;另外數據讀操作的時候,還要看數據在內存中是否命中,否則需要訪問更多的磁盤文件 。基于LSM樹實現的HBase的寫性能比MySQL高一個數量級,但是讀數據的性能要比MySQL低一個數量級 。
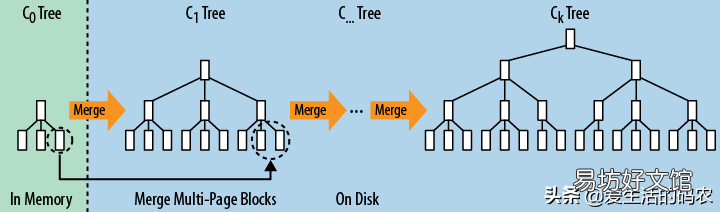
LSM樹原理把一棵大樹拆分成N棵小樹,它首先寫入內存中,隨著小樹越來越大,內存中的小樹會flush到磁盤中,磁盤中的樹定期可以做merge操作,合并成一棵大樹,以優化讀性能 。
文章插圖
文章插圖
LSM樹
補充:LSM-Tree全稱是Log Structured Merge Tree,是一種分層有序,面向磁盤的數據結構,其核心思想是充分了利用了,磁盤順序寫要遠比隨機寫性能高出很多的特性,如下圖示:
文章插圖
文章插圖
隨機性和順序寫的性能比對
圍繞LSM-Tree的原理進行設計和優化,以此讓寫性能達到最優,當然有得就有舍,這種結構雖然大大提升了數據的寫入能力,卻是以犧牲部分讀取性能為代價的,故此這種結構通常適合于寫多讀少的場景,這是HBase寫比讀速度快的根本原因所在 。
五 HRegionServer的工作機制5.1 HRegion分配機制一個 HRegion 只能分配給一個 HRegionServer,也就是說HRegionServer和HRegion的關系是一對多的關系 。master 記錄了HBase集群中哪些 HRegionServer 是可用的 。以及哪些 HRegion 已經分配給了哪些 HRegionServer,哪些 HRegion 還沒有分配 。
當HRegionServer需要分配的新的 HRegion時,Master 就會給這個 HRegionServer 發送一個裝載請求,把 HRegion 分配給這個 HRegionServer 。HRegionServer 得到請求后,就開始對此 HRegion 提供服務 。
5.2 HRegionServer上線
- Master使用Zookeeper來跟蹤HRegionServer的狀態 。
- 當某個HRegionServer啟動時,首先在Zookeeper上的/hbase/rs目錄下建立代表自己的znode 。
- 由于Master訂閱了/hbase/rs目錄上的變更消息,當/hbase/rs目錄下的文件出現新增或刪除操作時,Master可以得到來自Zookeeper的實時通知 。
- 因此一旦HRegionServer上線,Master能馬上得到消息 。
- 當RegionServer下線時,它和Zookeeper的會話就會斷開 。
- 當Master連續幾次和RegionServer都無法通信時,就可以確定HRegionServer和Zookeeper之間的網絡斷開了,或者是這個RegionServer掛了 。
① 首先是單點集中問題,我所見過的單點集中問題主要有下面幾種情況:
- RowKey前面的字符比較集中固定 。
- 集群節點過少 。
隨機字符(2位) + 時間位(14位)+ 業務編碼(4位)
親身檢測過:前后兩種方案對比,前者的MR程序跑了2個小時,后者只花了10分鐘 。
② RowKey的長度過于太長
在HBase中,RowKey、列族、列名等都是以byte[]的形式傳輸的 。RowKey的上限長度是64KB,但是我們使用HBase主要是為了讓它快,因此在實際的應用中,RowKey的大小不會超過100B 。這主要是從下面兩個方面考慮的 。
HBase的數據是存儲在HFile中的,RowKey是KeyValue結構中的一個域 。假設RowKey的大小是100B,那么1000萬條數據,RowKey可能就占用了1GB的空間,也會影響HBase的響應速度的 。
文章插圖
文章插圖
RowKey的設計原則
HBase中的MemStore和BlockCache,分別對應列族在Store級別的寫入緩存和RegionServer級別的讀取緩存 。如果RowKey過長,緩存中存儲數據的密度就會降低,影響數據落地或查詢效率 。
目前服務器一般都安裝64位操作系統,內存按照8B對齊,因此,在設計RowKey時候,一般考慮做成8B的整數倍,例如如16B或者24B 。同理,列族、列名的命名在保證可讀的情況下盡量短 。HBase官方不推薦使用3個以上列族,因此實際上列族命名幾乎都用一個字母,比如‘c’或‘f’ 。
6.2 使用壓縮技術HBase支持很多壓縮算法,而且能夠做到從列簇級別上進行壓縮 。壓縮可以減少網絡帶寬,同時也能夠加快數據的讀取,因此使用壓縮算法通常能帶來可觀的性價比 。

文章插圖
文章插圖
HBase支持的壓縮算法
【hbase三種查詢方式 hbase使用教程】注意:如果一張表已經使用了某種壓縮算法,那么現在想更改這張表的壓縮格式,要先將該表disable才能修改,之后再enable重新上線 。
推薦閱讀







- 蘋果手機型號查詢 iphone手機屏幕尺寸分別是多少
- 免費商標注冊查詢平臺 logo注冊查詢官網
- iPad序列號對照表 蘋果平板序列號查詢真偽
- 白菜炒咸了怎么辦啊
- 個人房產查詢app介紹 商品房買賣合同查詢網站
- linux更改主機名的三種方法 linux怎么修改主機名命令
- 今日汝州雜毛豬價,汝州天氣預報15天查詢
- 百度競價推廣出價技巧 關鍵詞競價查詢
- ps瘦臉教程三種方法 ps如何去黑眼圈眼袋
- redis集群三種方式 redis線程池作用